
There is a new commission, codename: pass tech. You are entitled to the design, test, code, and document this new software. Be ready. The purpose of that software is to share snippets of information across the federation. There is no control, access control, or access control list, the published texts are public.
Your task is easy: create a software that will associate a text string with a unique identifier, and store that for later retrieval.
The first step is to describe the intended behavior with a test, let’s open a mighty code block that will host a few parentheses:
(define check-pass-tech-099
(lambda ()
;; Generate a random text
(define text (pass-tech-lorem-ipsum))
;; Add the text to pass-tech
(define uid (pass-tech-add text))
;; Check that the saved text is really saved, and
;; that it is the same as the one create above
(assert (string=? text (pass-tech-ref uid)))))Good. There are two procedures that are necessary for this software pass-tech-add and pass-tech-ref. Looking through the reference procedure index reveals there is no procedure called pass-tech-lorem-ipsum so that needs to be defined too.
Let’s start with test helper pass-tech-lorem-ipsum, then the easiest procedure namely pass-tech-ref, and finish with slightly more involved pass-tech-add.
For hosting the data, an ordered key-value store is used. It is an ordered mapping of bytevectors associated with bytevectors. They are helper procedures called byter-pack, and byter-unpack that allow to work with the database without dealing with bytes. Tho, dwelling on bytes can be helpful, among other things, to avoid over-specification, hence keeping the software flexible. That will be illustrated in pass tech. The fact that mapping’s keys are sorted will not be useful in the current context.
For the current streak, there is a set of strings associated with an identifier. To keep things simple, identifiers will be bytevectors. Hence the data model looks as follow:
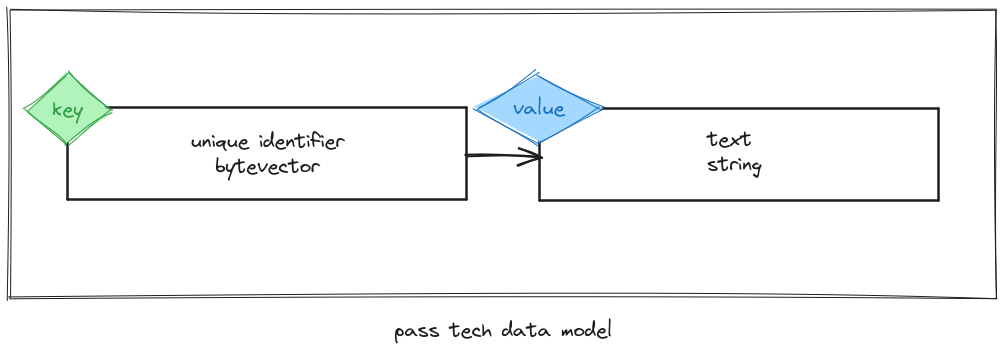
pass-tech-lorem-ipsumLet’s start with pass-tech-lorem-ipsum. The number of words is not specified, but my pet came up after while with the number 42, let’s use that. pass-tech-lorem-ipsum will produce a string with words taken from the original lorem ipsum text, where words are placed randomly. No need, this time, to dig the local public library, a paragraph of lorem ipsum text is copy-pasted here:
(define pass-tech-lorem-ipsum-paragraph "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vestibulum malesuada nisi mattis, gravida arcu eget, egestas mi. Duis pretium risus gravida rutrum laoreet. Mauris facilisis nunc sit amet ullamcorper dignissim. In id purus fringilla, tempor magna et, pharetra arcu. Cras finibus faucibus purus, sit amet fringilla massa suscipit efficitur. Donec id neque eu mauris fringilla efficitur. Suspendisse rhoncus neque eget massa bibendum, nec semper eros gravida. Duis semper tortor in enim sagittis pretium. In in justo dui.")Next thing is to split that string into words using punctuation and space as split-points. To keep it simple assume the input string only has letters from the string pass-tech-letters:
(define pass-tech-letters "abcdefhijklmnopqrstuvwxyz")What is not a char from that string is considered punctuation, or space hence a split-point. They are several ways to do that, efficient, less efficient… Start with a test to clear your mind with a precise goal:
(define check-passtech-000
(lambda ()
(define text "hello, people!")
(define given (pass-tech-text-split text))
(define expected (list "hello" "people"))
(assert (equal? expected given))))In essence, what this procedure does is split a string into words taking into account the simplistic definition for letters in the string pass-tech-letters. They are prolly wholly fully general approach across unicode codepoints, with support a world wide diversity of scripts and whatnot… For the time being, let’s ship our immediate need, define pass-tech-text-split:
(define pass-tech-text-split
(lambda (string)
;; Iterate over the string as chars
(let loop ((chars (string->list string))
;; The output is a list of string,
;; using chars as intermediate representation
(out '(())))
(if (null? chars)
;; The first item in the output list
;; is a list of chars, convert to string before
;; returning
(if (null? (car out))
(cdr out)
(cons (list->string (reverse (car out)))
(cdr out))
;; Is the next char a split point?
(if (member (car chars) pass-tech-letters)
;; no, add it to the output
(loop (cdr chars) (cons
(cons (car chars)
(car out))
(cdr out)))
;; Yes, it is space or punctuation,
;; create a split point now, if we accumulated
;; any chars
(if (null? (car out))
;; there is already an empty split point
(loop (cdr chars) out)
(loop (cdr chars)
(cons* (list)
(list->string (reverse (car out)))
(cdr out)))))))))Inside the loop aka. named let, there is two arguments chars, and out:
chars is the list of character objects that makes the original string that were not processed yet;out is the variable holding the output of the function, it is a list of words; except the first item that rely on an intermediate representation: a list of chars in reverse order where are accumulated chars for a word until a split point is met.The code must take care of the fact that a char can be a letter, or split point, and several split point can be met before meeting a new letter; also a word can be a single letter, but not the empty string.
Next, let’s choose 42 times a word from the list produced by pass-tech-text-split when passed pass-tech-lorem-ipsum-paragraph to construct pass-tech-lorem-ipsum:
(define pass-tech-lorem-ipsum-words
(pass-tech-split (string-downcase pass-tech-lorem-ipsum-paragraph)))
(define pass-tech-lorem-ipsum
(lambda ()
(string-join " "
(map (lambda _ (random-choice pass-tech-lorem-ipsum-words))
(iota 42)))))That is it. The procedure pass-tech-lorem-ipsum will choose 42 words and join them to build a random lorem ipsum text.
pass-tech-refA text in pass tech is identified with a bytevector, and the text is a string. Retrieving a text is as simple as retrieving the value associated with the given bytevector identifier with database-ref. The database associate a bytevector to a bytevector, hence the return value of database-ref is also a bytevector, let’s translate it, decode it into its original form, and expected form a string with byter-unpack. Long story is in fact short, define pass-tech-ref:
(define pass-tech-ref
(lambda (uid)
(byter-unpack
(call-with-transaction
(lambda (tx)
(database-ref uid)))))The procedure pass-tech-ref will take an identifier that is a bytevector uid, then:
call-with-transaction, it is important to always think about transactions, even if in this case trivial because there is only a single database procedure that is called. The procedure call-with-transaction describe the extent of the database operations that are inside the procedure passed as argument. It makes it possible for the database engine to reason about ACID guarantees, that we will dive into in follow up sections, so stay tuned.database-ref.byter-unpack takes a bytevector as argument that should have been constructed by byter-pack and returns whatever is encoded in the bytevector, in this case “by construction” that we will see in the next section, it returns a string. It is done outside the extent of the transaction because the smallest, hence the fastest your transaction procedure are the faster the database will be globally, across concurrent transactions, that is a faster, and more efficient software.Neat.
pass-tech-addRemember the test case generate a random text, and add it to the database associated with a unique identifier. The latter is very important an identifier is allocated that is unique and associated with the text. Let’s generate a random bytevector of 16 bytes and with the well deserved legacy of engineered luck walk away with the assurance and no guilt that the identifier is unique. That’s it define pass-tech-unique-identifier and pass-tech-add:
(define pass-tech-unique-idenfifier
(lambda ()
(apply bytevector (map (lambda _ (random 256)) (iota 16)))))
(define pass-tech-add
(lambda (text)
(define uid (pass-tech-unique-identifier))
(call-with-transaction
(lambda ()
(database-set! uid (byter-pack text))))
uid))Wrapping up:
pass-tech-unique-identifier generate a bytevector of 16 bytes, with enough entropy, and a random seed that is set carefully (!) it should be unique;pass-tech-add the unique identifier is generated outside the extent of the transaction, because it is more efficient, it was explained before that the smaller the transaction extents the better for application efficiency. That bytevector, dubbed uid, is used as the key to store the text;byter-pack;uid to be cared for, loved, passed, and published in the next press release.pass tech is coming up nicely, and swiftly. The bulk of the work was to create a test procedure. Most of the complexity related to storage is factored inside the database’s procedures. There is a couple of good to know thing related to databases:
byter-pack, and byter-unpack are useful ;A low complexity, is correlated with low coupling, and that is why it is easier to reason about a system.
An example of this is the unique identifier that, in the current context, is a bytevector, and that makes it easy to pass the identifier to database-set. Another bigger example, and that is the topic of this series of tutorials is the database with, the scifi buzz hype ordered mapping of bytevectors. Mappings are pervasive in mordern software engineering, granted, they are sometime overkill, but in the case of data management, and data storage they are the gist of the topic: simple, and enough complex to be a minimal abstraction.